서브쿼리
- SQL 문 내부에 작성되는 SQL문 (ORDER BY 절 사용 불가)
- 서브쿼리문이 필요할 경우 서브쿼리문을 먼저 작성하고 메인쿼리문 작성
select last_name, salary from employees
where salary > (select avg(salary) from employees);
Problem
Q. 'chen'사원보다 salary를 많이 받는 사원 목록을 출력
select last_name, salary from employees
where salary >= (select salary from employees where last_name='Chen')
order by salary;
Q. '정의찬'과 부서(DEPT)가 다르지만 동일한 업무(JOB)을 수행하는 사원 목록을 출력
select ename, job, dno from emp
where (job, dno) in (select job, dno from emp where ename = '정의찬');
select eno, ename, job, dno from emp
where dno != (select dno from emp where ename = '정의찬')
and job = (select job FROM emp where ename = '정의찬');
Q. '관우'보다 일반화학과목의 학점이 낮은 학생의 명단을 출력
select s.sno, sname, grade
from student s, course c, score r, scgrade g
where s.sno = r.sno
and c.cno = r.cno
and cname = '일반화학'
and result between loscore and hiscore
and grade > (select grade from student s, course c, score r, scgrade g
where s.sno = r.sno
and c.cno = r.cno
and cname = '일반화학'
and sname = '관우'
and result between loscore and hiscore);
select max(count(*)) from student
group by major;
select major from student
group by major
having count(*) = (select max(count(*)) from student group by major);
Q. 학생중 기말고사 평균성적이 가장 낮은 학생의 정보를 검색
select min(avg(result)) from score
group by sno;
select s.sno, s.sname
from student s, score sc
where s.sno = sc.sno
group by s.sno, s.sname
having avg(result) = (select min(avg(result)) from score group by sno);
Q. 화학과 1학년 학생중에 평점이 평균이하인 학생을 검색
select * from student
where major = '화학'
and syear = 1
and avr < (select avg(avr) from student
where major = '화학'
and syear = 1);
Multi column, Multi row
| 연산자 | 기능 |
| IN | 검색된 값 중에 하나만 일치하면 참 |
| ANY | 검색된 값 중에 조건에 맞는 것이 하나 이상이면 참 |
| ALL | 검색된 값과 중에 조건에 모두 일치하면 참 |
- column > max () = column > ALL(서브쿼리) : 가장 큰 값보다 크다. (모든 값보다 크다.)
- column < min() = column < ALL(서브쿼리) : 가장 작은 값 보다 작다. (모든 값보다 작다.)
- column < max() = column < ANY(서브쿼리) : 가장 큰 값보다 작다.
- column > min() = column > ANY(서브쿼리) : 가장 작은 값보다 크다.

ROWNUM
- Oracle 자체적 기능으로 select 구문을 통해 실행될 때,
rownum이라는 이름의 Column이 생성되고 row 개수에 맞게 1부터 순서대로 Indexing 한다.
- row 순서가 5 이하인 row를 출력
select rownum, alias.*
from (select employee_id, last_name, hire_date from employees
order by hire_date) alias
where rownum <= 5;
- rownum 만 가지고는 중간에 있는 data 예를 들면 아래와 같이 index 5 ~ 8을 추출할 수 없다.
이를 해결하기 위해 서브 쿼리를 사용해야 한다.
( rownum : ';'까지의 과정이 끝나고 row의 개수에 맞게 Indexing 하여 출력)
select rownum, temp.*
from (select * from board
order by seq desc)temp
where rownum between 5 and 8;
--문제 해결
select * from(
select rownum as row_num, temp.*
from (select * from board
order by seq) temp
)where row_num between 5 and 8;
Problem
Q. 직무(job_id)별 최대 급여자의 사원내역을 출력
select max(salary) from employees
group by job_id;
select employee_id, last_name, salary, job_id from employees
where (job_id, salary) in (select job_id, max(salary) from employees
group by job_id);
Q. 01번(부서번호) 부서원들과 보너스 (comm)가 같은 사원을 검색
select comm from emp
where dno = 01;
select * from emp
where comm in (select comm from emp
where dno = 01);
Q. 부서번호 30번 최대급여자보다 급여가 높은 사원을 출력하라.
select max(salary) from employees
where department_id = 30;
select * from employees
where salary > (select max(salary) from employees
where department_id = 30)
order by salary asc;
select * from employees
where salary > ALL(select salary from employees
where department_id = 30)
order by salary asc;
Q. 부서번호 30번 최대급여자보다 급여가 작은 사원을 출력하라.
select * from employees
where salary < ANY(select salary from employees
where department_id = 30)
order by salary desc;
select * from employees
where salary < (select max(salary) from employees
where department_id = 30)
order by salary desc;
Q. '손하늘'과 동일한 관리자(mgr)의 관리를 받으면서 업무도 같은 사원을 검색
select * from emp
where (mgr, job) in (select mgr, job from emp
where ename = '손하늘');
Q. 화학과 학생과 평점이 동일한 학생을 검색
select * from student
where avr = any(select avr from student
where major = '화학')
order by avr;
Q. 화학과 학생과 같은 학년에서 평점이 동일한 학생을 검색
select * from student
where (syear, avr) in (select syear, avr from student
where major = '화학');
Q. 기말고사 평균성적이 '핵화학' 과목 평균 성적보다 우수한 과목번호, 과목명, 담당교수 검색
select avg(s1.result)
from score s1 join course c1
on c1.cname = '핵화학' and c1.cno = s1.cno
group by s1.cno;
select s.cno, c.cname, p.pname
from score s join course c
having avg(s.result) > (select avg(s1.result) from course c1 join score s1
where c1.cname = '핵화학' and c1.cno = s1.cno);
select cno from course
where cname = '핵화학'
select avg(result) from score
where cno = (select cno from course where cname = '핵화학');
select c.cno, c.cname, p.pname, avg(result)
from score r, professor p, course c
where r.cno = c.cno
and p.pno = c.pno
group by c.cno, c.cname, p.pname
having avg(result) > (select avg(result) from score
where cno = (select cno from course
where cname = '핵화학'));
* 이 문제로 생각해보기 위한 코드들
--핵화학 의 평균
select avg(s1.result)
from score s1 join course c1
on c1.cname = '핵화학' and c1.cno = s1.cno
group by s1.cno;
--
select cno, avg(result)
from score
group by cno;
-- 각 과목별 핵화학 보다 평균이 높은 과목
select s.cno, c.cname, avg(s.result)
from score s ,course c
group by s.cno, c.cname
having avg(s.result) > (select avg(s1.result) from course c1 join score s1
on c1.cname = '핵화학' and c1.cno = s1.cno group by s1.cno)
;
-- 서브 쿼리 문의 테이블 변수를 외부 쿼리와 같게해도 동작
select s.cno, c.cname, avg(s.result)
from score s ,course c
where s.cno = c.cno
group by s.cno, c.cname
having avg(s.result) > (select avg(s.result) from course c join score s
on c.cname = '핵화학' and c.cno = s.cno group by s.cno);
-- Oracle
select c.cno, c.cname, p.pname, avg(result)
from score r, professor p, course c
where r.cno = c.cno
and p.pno = c.pno
group by c.cno, c.cname, p.pname
having avg(result) > (select avg(result) from score
where cno = (select cno from course
where cname = '핵화학'));
--Ansi
select s.cno, c.cname, p.pname, avg(s.result)
from score s join course c
on s.cno = c.cno
join professor p
on c.pno = p.pno
group by s.cno, c.cname, p.pname
having avg(s.result) > (select avg(s1.result) from course c1 join score s1
on c1.cname = '핵화학' and c1.cno = s1.cno group by s1.cno);Oracle 문은 직관적이라서 구문 작성이 쉬운 반면에
Ansi 문은 문법이 상대적으로 고정적이라 구문 작성이 살짝 까다롭게 느껴진다.
SQL문을 프로그램에서 읽고 처리하는 순서가 잘 이해가 안되었는데, 이 문제를 통해 조금은 이해한 것 같다.
이 문제의 Ansi 코드 기준으로 미리 적어놓고 나중에 제대로 이해하면 복습하는 과정에서 수정하도록 하겠다.
1. select ... from 구문을 통해 먼저 출력할 표의 column의 이름을 입력'만' 받는다.
이를 통해 버퍼(?)에 해당 Column 들을 등록한다.
2. 그 이후에는 목적에 맞게 조건 구문을 입력해준다.
테이블 간의 조건 구문을 만족한다면 (s.cno = c.cno) 만족하는 course 의 row를 score 의 뒤에 이어 붙인다.
(비교 컬럼의 중복 제거)
예를 들어, score의 column이 ( SNO, CNO, RESULT ) 이고 course의 column이 ( CNO, CNAME, ST_NUM, PNO ) 라면
이 과정의 버퍼에는 column이 ( SNO, CNO, RESULT, CNAME, ST_NUM, PNO ) 인 테이블이 존재하게 된다.
* 만약 적절한 조건 구문을 생성하지 못한다면,
예를 들어 2개의 테이블을 사용하는 select...from 구문이고 A 테이블의 크기 N, B 테이블의 크기 M이라면
row의 크기가 N * M인 테이블이 버퍼에 생성될 것이다.
3. AVG와 같은 병합이 선두로 필요한 연산 함수에 대해서는 GROUP BY절이 선행되어야 한다.
주의할 점이 있는데, GROUP BY를 통해 select...from 구문에서 언급한 AVG와 같은 연산함수가 아닌 함수는
모두 group by 를 통해 그룹화 시켜주어야한다.
앞서 2.에서 버퍼에 모든 컬럼이 들어가는 것처럼 이야기했지만, 사고의 편의를 위함이였고,
select...from에서 언급된 column만 잇는다고 생각하면 된다.
그 다음 가장 작은 범주 부터 그룹화를 통해 연산함수를 통해 나타낼 범위를 나눈다.
(이게 표현이 어려운데.... 예를 들어 아래와 같은 데이터가 있다면,
그리고 표시하지는 않았지만, 각 row가 숫자 데이터를 가지고 있다면
평균을 내기위해서는 3개의 column을 모두 group by를 통해 정리해주어야 한다.
이 부분은 논리적인 이해보다는 사용 용도에 따른 이해가 맞는 것 같다.)
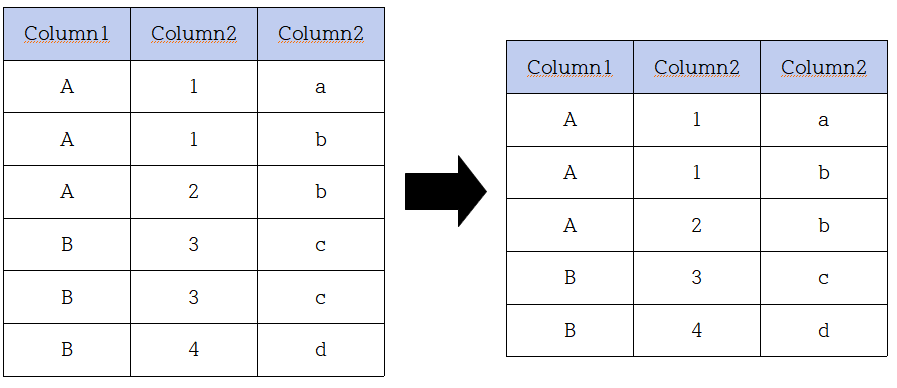
4. 그룹화된 데이터를 처리해주는 HAVING 절을 조건을 처리해준다.
5. 마지막으로 다시 select...from 절로 돌아가서 Buffer에 있는 데이터를 순서에 맞게 출력해준다.
Q. 전체 사원 중 allen과 같은 직책(job)인 사원들의 사원 정보, 부서 정보를 다음과 같이 출력하는 sql문을 작성
select e.job, e.empno, e.ename, e.sal, d.deptno, d.dname
from emp e join dept d
on e.deptno=d.deptno
and e.job = (select job from emp
where ename='ALLEN')
order by sal desc;
Q. 전체 사원의 평균 급여(SAL)보다 높은 급여를 받는 사원들의 사원 정보, 부서 정보, 급여 등급 정보를 출력하는
sql문을 작성
select e.empno, e.ename, d.dname, e.hiredate, d.loc, e.sal, s.grade
from emp e inner join dept d
on e.deptno = d.deptno
--서브 쿼리에 group by는 select...from절에서 column을 명시하지 않았기 때문에 없어도 된다.
and sal > (select avg(sal) from emp)
inner join salgrade s
on e.sal between losal and hisal
order by sal desc, empno asc;
Q. 10번 부서에 근무하는 사원 중 30번 부서에는 존재하지 않는 직책을 가진 사원들의 사원 정보, 부서 정보를
다음과 같이 출력하는 SQL문을 작성
select e.empno, e.ename, e.job, e.deptno, d.dname, d.loc
from emp e inner join dept d
on e.deptno = 10
and e.deptno = d.deptno
and e.job != all(select job from emp
where deptno = 30);
Q. 직책이 SALESMAN인 사람들의 최고 급여보다 높은 급여를 받는 사원들의 사원 정보, 급여 등급 정보를 다음과 같이 출력하는 SQL문을 작성
select e.empno, e.ename, e.sal, s.grade
from emp e inner join salgrade s
on sal > all(select sal
from emp e
where job = 'SALESMAN')
and sal between losal and hisal
order by empno asc;select e.empno, e.ename, e.sal, s.grade
from emp e inner join salgrade s
on sal > (select max(sal)
from emp e
where job = 'SALESMAN')
and sal between losal and hisal
order by empno asc;
트랜잭션 (Transaction)
- DML (insert, update, delete) 대상
- 여러 명령어가 정상적으로 처리되야 종료되며 중간에 오류 발생시 전체 취소
(데이터의 일관성 및 데이터의 복구를 위함)
- 전체 성공 : commit, 실패 : rollback
'kosta > [DB]Oracle' 카테고리의 다른 글
| [Oracle] SQL문 정리 5 (0) | 2022.03.14 |
|---|---|
| [Oracle] SQL문 정리 4 (1) | 2022.03.11 |
| [Oracle] SQL문 정리 2 (1) | 2022.03.09 |
| [Oracle] SQL문 정리 (0) | 2022.03.07 |
| [DB] 1. 데이터베이스 소개 (0) | 2022.03.04 |


댓글