1. 변수
1.1 변수(variable)란?
- 단 하나의 값을 저장할 수 있는 메모리 공간
1.2 변수의 선언과 초기화
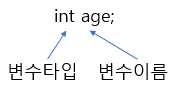
- 변수 타입
- 저장하려는 값의 종류 (정수, 실수, 문자 등)에 따라 알맞은 타입을 지정 (int, double, char etc...)
- 변수 이름
- 변수에 붙인 이름
- 즉, 변수가 저장되는 메모리 공간의 이름 (다른 변수와 이름이 중복되어서는 안 됨)
변수의 초기화
메모리는 공유 자원이므로, 변수 선언 시 할당받은 메모리 공간은 이전에 다른 프로그램에 의해 사용된 쓰레기 값이 남아 있을 수 있다. 따라서 변수를 사용하기 전에 반드시 초기화(initialization)를 해야 한다.
(하지만 변수의 종류나 쓰임에 따라 초기화를 생략할 수도 있다.
ex. 지역변수는 사용되기 전에 반드시 초기화
클래스 변수, 인스턴스 변수는 초기화 생략 가능)
대입 연산자 '='
오른쪽의 값(value)을 왼쪽(variable)에 저장
두 변수의 값 교환하기
int x = 1; int y = 2;일 때,
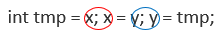
윗 줄처럼 한 줄로 쓰면 꼬리물기인 것이 보일 것이다.
1.3 변수의 명명규칙
식별자(identifier) : 변수의 이름처럼 프로그래밍에서 사용하는 모든 이름
- 대소문자가 구분되며 길이에 제한이 없다.
- ex. Var와 var은 다른 식별자
- 예약어를 사용해서는 안된다.
- 숫자로 시작해서는 안된다.
- ex. var10 (O), 10var(X)
- 특수문자는 '_'와 '$'만을 허용
예약어 ( = keyword or reserved word)
프로그래밍 언어의 구문에 사용되는 단어
쉽게 말해 이미 쓰임이 지정되어 있기 때문에 식별자로 사용할 수 없다.

권장 규칙
- 클래스 이름의 첫 글자는 항상 대문자
- 변수와 메서드 이름의 첫 글자는 항상 소문자
- 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자
ex. BufferedReader (클래스 이름), camelCase (변수, 메서드 이름) - 상수의 이름은 모두 대문자, 여러 단어로 이루어진 경우 '_'로 구분
ex. MAX, MIN_NUMBER
2. 변수의 타입
기본형과 참조형
- 기본형 (primitive type)
- 실제 값을 저장
- 정수(byte, short, int, long), 실수 (float, double), 문자 (char), 논리 (boolean)
- 참조형 (reference type)
- 어떤 값이 저장되어 있는 메모리의 주소를 저장
- 객체의 주소를 저장
자바는 참조형 간의 연산이 불가능
참조형 변수 선언 방법
- 변수의 타입으로 클래스의 이름을 사용 (클래스의 이름이 참조 변수의 타입)
- 즉, 새로운 클래스를 작성한다는 것은 새로운 참조형을 추가하는 것
- 클래스이름 변수이름; <= 오른쪽과 같이 변수의 타입이 기본형이 아닌 것들은 모두 참조변수
ex.

- Date 클래스 타입의 참조변수 today를 선언 (참조변수의 초기화)
- 즉, Date객체를 생성하고, 그 주소를 today에 저장
- 참조변수는 null 또는 객체의 주소를 값으로 갖는다.
* 객체를 생성하는 연산자 new는 객체의 주소를 반환되고, 이 주소는 대입연산자(=)을 통해 참조변수에 저장
* 객체의 주소 : 참조형 변수는 null or 4 byte (0x0 ~ 0xFFFFFFFF)를 값으로 갖는다.
단, JVM이 64bit라면 (32bit가 아니고) 참조형 변수의 크기는 8byte
2.1 기본형(primitive type)
- 논리형 (boolean - 1byte)
- true와 false 중 하나의 값을 가짐 (1, 0으로 대응 가능)
- 다른 기본형과 연산이 불가능
- 문자형 (char - 2byte)
- 하나의 변수에 하나의 문자만 저장 가능
- 문자를 유니코드(정수)로 저장 => 정수 or 실수와 연산 가능
- 정수형 (byte, short - 2byte, int - 4byte, long - 8byte)
- 정수를 저장하는 데 사용
- byte : 이진 데이터를 다룰 때 사용
- short : C언어와의 호환을 위해서 추가
- 실수형 (float - 4byte, double - 8byte)
* boolean을 제외한 나머지 기본형은 서로 간의 연산과 변환이 가능
* 정수형 저장 시, 일반적으로 int가 가장 많이 사용
이는 int가 JVM의 처리 단위인 32bit(4byte)와 같으므로 가장 효율적으로 사용 가능
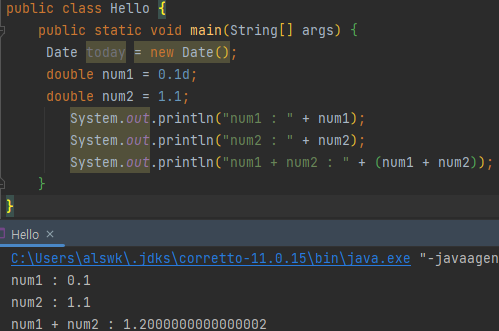
* 실수형은 부동소수점 방식을 사용하여 정수형보다 훨씬 넓은 범위를 표현할 수 있으나,
정확한 값이 아닌 가까운 값으로 변환하여 표현한다. 이는 아래를 보면 확인 가능하며
이때 소수점 몇 번째 자리까지 정확한지를 정밀도라고 한다. (float : 7자리, double : 15자리)
구체적인 방법은 뒤에서 배울 것
2.2 상수와 리터럴 (constants & literal)
상수(constant)
- 변수와 마찬가지로 값을 저장할 수 있는 공간이지만 최초 선언 및 초기화 이후에는 값을 변경할 수 없음
final int MAX_NUM = 100;- 반드시 선언과 동시에 초기화
- 상수의 이름은 모두 대문자로 하는 것이 관례이며, 여러 단어로 이루어진 경우 '_'로 구분
- * JDK 1.6부터 상수는 선언과 동시에 초기화를 진행하지 않아도 되지만,
- 사용하기 전에는 반드시 초기화가 이루어져야 함
리터럴(literal)
- 수학적으로 상수라고 불리는 숫자
- ex. 3.14, 1, 10, 100, 'A', 'B'
다시 정리하자면,
- 변수(variable) : 하나의 값을 저장하기 위한 공간
- 상수(constant) : 값을 한 번만 저장할 수 있는 공간
- 리터럴(literal) : 그 자체로 값을 의미하는 것
ex.
int year = 2022;
final int MAX_NUM = 500;위에서 year : 변수, 2022와 500은 리터럴, MAX_NUM은 상수
상수가 필요한 이유
int triangleArea = (20 * 10) / 2;
int rectangleArea = 20 * 10;위를 보면, 삼각형과 사각형의 넓이를 data로 하는 두 변수 triangleArea와 rectangleArea가 있다.
만약 가로, 세로의 값 20, 10이 변경된다면 두 변수에서 직접 20과 10을 수정해주어야 한다.
final int WIDTH = 20;
final int HEIGHT = 10;
int triangleArea = (WIDTH * HEIGHT) / 2;
int rectangleArea = WIDTH * HEIGHT;이때, 이 값들이 위와 같이 상수로 지정되어 있다면, 상수의 값을 변경해주기만 하면 하단의 모든 코드에 그 값들이 적용되어 이해를 쉽게 돕고, 직관적으로 코드를 이해할 수 있다.
리터럴의 타입과 접미사
- 변수에도 타입이 있는 것처럼 literal에도 타입이 있다.
- 변수의 타입은 저장될 값의 타입, 즉 리터럴의 타입에 의해 결정되므로
- 리터럴에 타입이 없다면 변수의 타입도 필요 없을 것

- 정수형 (기본 자료형 : int)
- long 타입의 리터럴 : 접미사 l or L
- ex. long num = 100L
- 접미사가 붙지 않은 정수는 int 타입의 리터럴
- byte와 short타입은 별도의 리터럴 없이 int 타입의 리터럴을 통해 값을 저장
- 실수형 (기본 자료형 : double)
- float 타입의 리터럴 : 접미사 f or F
- double 타입의 리터럴 : 접미사 d or D (생략 가능)
- 10의 제곱 리터럴 E or e
- ex. 3.14e2 = 314, 1e-1f = 0.1f
- 16진
- * 리터럴은 대문자를 사용하는 것이 일반적
- 2진수 : 0b or 0B
- ex. 0b01 = 1, 0b11 = 3
- 8진수 : 0
- ex. 05 = 5, 012 = 10
- 16진수 : 0x or 0X
ex. 0x10 = 16, 0xF = 15 - * JDK 1.7부터 정수형 리터럴의 중간에 구분자 '_'을 사용하여 큰 숫자를 편하게 읽을 수 있음
ex. long num = 100_000_000_000L;
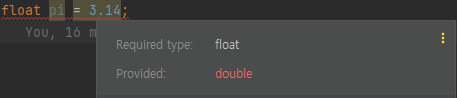
타입의 불일치
변수의 타입과 리터럴의 타입이 일치하지 않더라도,
변수의 타입이 더 크다면, 더 작은 크기의 리터럴을 저장할 수 있다.
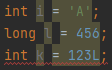
제일 아래줄의 경우 변수타입의 크기보다 리터럴의 크기가 더 크기 때문에 오류가 발생
문자 리터럴과 문자열 리터럴
- 문자 리터럴 '' : char
- 'A'와 같이 문자 하나
- 문자열 리터럴 "" : string
- "AB"와 같이 둘 이상의 문자들의 집합
- 문자열 리터럴은 ""와 같이 빈 문자열을 넣는 것이 허용
- (C++ 기준 '\0'만 저장됨, '\0'는 문자열의 끝을 알리는 기호)
- 문자 리터럴은 ''와 같이 빈 문자열을 넣는 것을 허용하지 않음
String
- 원래 String은 클래스이므로, 아래와 같이 객체를 생성 후 사용해야 하지만,
- 예외적으로 기본형처럼 사용하도록 허용
String name = new String("Name");
//이를 아래와 같이 작성하는 것을 허용
String name = "Name";- 덧셈 연산자 '+'을 사용하여 문자열 간의 결합이 가능하며,
- 문자열과 다른 기본형을 결합하는 경우, 다른 기본형을 문자열로 변환 후
- 문자열 간에 결합을 진행한다.
- ex.
true + "" => true
null + "" => null
5 + 5 + " " => "10 "
2.3 형식화된 출력 - printf()
- 지시자(specifier)를 통해 변수를 원하는 형태로 출력 가능 (println()은 불가)
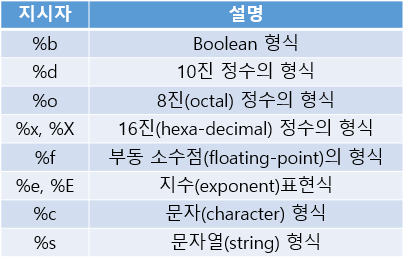
int age = 20;
int hex = 0xFFFF;
System.out.printf("age:%d", age); // age:20
System.out.printf("hex=%#x", hex); // hex=0xFFFF
System.out.printf("hex=%x", hex); //hex=FFFF
// '#'의 경우 앞에 진수를 표현 (16진수 0x, 8진수 0)
출력 공간 지정
아래의 예제를 통해 활용방법을 쉽게 이해 가능
int amount = 5;
System.out.printf("amount=[%3d]%n", amount); //amount=[ 5]
System.out.printf("amount=[%-3d]%n", amount); //amount=[5 ]
System.out.printf("amount=[%03d]%n", amount); //amount=[005]
10진수를 2진수로 출력 방법
int binNum = 0b101;
System.out.printf("binNum=0b%s", Integer.toBinaryString(binNum));
//binNum=101
char 타입의 변수 유니코드 확인 방법
C언어와는 반대로, Java는 char타입의 변수를 지시자 %d를 통해 출력할 수 없다.
따라서 아래와 같이 (int)와 같은 과정을 통해 형 변환을 해주어야 한다.
System.out.printf("c = %c, %d", c, (int)c);
* 당연한 얘기일 수도 있지만, 변수에 n진 리터럴 값을 저장하면 2진수로 저장된다.
지정된 진수로 변환된 후, 출력될 뿐이다.
println() 같은 경우 기본적으로 10진수의 형태로 출력된다. 즉 변수에 16진수 리터럴 형태로 값을 저장하더라도
prinln()을 통해 출력 시 10진수로 변환되어 출력된다.
실수의 출력 공간 지정
- %f (기본적인 실수형 지시자)
- 기본적으로 소수점 아래 6자리까지 표현 (7번째 자리에서 반올림)
- %e (지수 형태 지시자)
- %전체자리.소수점아래자리f와 같은 형태로 출력 공간을 지정하며, 전체 자리의 개수에는 소수점 또한 포함
또한, '전체자리'의 크기가 표현하려는 수보다 작더라도 표현하려는 수는 모두 표현되고,
'소수점아래자리'의 크기는 무조건 보장된다. (아래 예제의 마지막 줄을 통해 확인 가능)
즉. '전체자리'라 함은 총길이를 제한하는 것이 아닌, 최소 길이를 보장한다라는 느낌으로 이해하면 좋을 것 같다
float f1 = .10f;
double d = 123.123456789;
System.out.printf("f1=%f%n", f1); //f1=0.100000
System.out.printf("f1=%e\n", f1); //f1=1.000000e-01
System.out.printf("d=%f\n", d); //d=1.234568
System.out.printf("d=%16.10f\n", d);//d= 123.1234567890
System.out.printf("d=%1.10f\n", d); //d=123.1234567890
문자열의 출력 공간 지정
- 정수와 비슷하게 숫자, '-'를 통해 최소 출력 공간 확보 및 좌측 정렬을 시행할 수 있다.
- 추가적으로 %.Ns와 같은 형식으로 지정된 문자열을 N개만큼만 출력할 수 있다.
String str = "abcdefg";
System.out.printf("str=%10s", str); //str= abcdefg
System.out.printf("str=%.3s", str); //str=abc
System.out.printf("str=%10.3s", str); //str= abc
2.4 화면에서 입력받기 - Scanner
뒷 장에서 자세히 다루나 미리 예습한다는 느낌으로 가볍게 학습
//java의 모든 util library를 import
//Scanner는 import java.util.Scanner에 정의되어 있음
import java.util.*;
public class ScannerEx {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
//enter(개행문자 '\n or %n'을 기준으로 input에 저장)
String input = scanner.nextLine();
//문자열 input을 int형으로 변환
int num = Integer.parseInt(input);
}
}
3. 진법
3.1 10진법과 2진법
- 에니악 => 10진법 사용 => 전압의 불안정으로 한계
- 에드박 => 에니악의 단점을 보완하기 위해 2진법으로 설계 => 성공적!
- 컴퓨터는 입력받은 모든 데이터를 2진수로 변환하여 저장
3.2 비트와 바이트
- 비트(bit, binary digit) : 한 자리의 2진수, 컴퓨터가 값을 저장하는 최소 단위
- 8bit = 1byte (데이터의 기본 단위)
- word
CPU가 한 번에 처리할 수 있는 데이터의 크기
32bit 컴퓨터에서는 word가 4byte(32bit)
64bit 컴퓨터에서는 word가 8byte(64bit) - nibble : 4bit, 16진수 1자리를 저장할 수 있는 단위
- n bit로는 2n개의 수를 표현 가능하며 10진수로는 0~2n-1사이의 값을 표현 가능
3.3 8진법과 16진법
- 8진수
- 1자리를 3bit로 표현, 0~7
- 16진수
- 1자리를 4bit로 표현, 0~F (A=10, B=11, C=12, D=13, E=14, F=15)
3.4 정수의 진법 변환 및 3.5 실수의 진법 변환
글로 작성하기는 어려워서 다시 책을 보자!
3.6 음수의 2진 표현 - 2의 보수법
1의 보수와 2의 보수를 이해하자!
● 정수 표현 컴퓨터는 N개의 비트를 이용해 2^N개의 정수만 표현할 수 있습니다. 이러한 방식을 이용해서 수를 표현해야 하기 때문에 쉽지 않습니다. 또한 정수는 음의 정수와 양의 정수로 나누
ndb796.tistory.com
N의 보수 : 두 수의 합이 진법의 밑수(N)가 되게 하는 수
- 2의 보수 :
ex. 이진수 0101의 2에 대한 보수는 1011 (두 수의 합이 10000, 즉 24(N=2)이 되도록 하는 이진수)
2의 보수가 필요한 이유 (사실과 추측이 난무...)
- 컴퓨터는 가산기를 통한 덧셈 연산만 진행
따라서 뺄셈을 보수라는 개념을 통해 구현
ex. 이진수 10000(즉, 24)은 십진수로 16이지만,
4bit 이진수에서는 제일 앞의 1이 버려지고 0000만 남게 되어 컴퓨터는 0으로 인식 - 이 원리를 사용하여 이진수 변수의 MSB 양수(0)/음수(1)를 표현하는 bit로 지정 (이를 2의 보수법이라고 함)
- 또한, 이진수에서 양수 (위의 0101)의 보수가 되는 음수(1011)의 경우 십진수 기준으로 합이 0이 되도록 설계
(0101은 십진수와 2의 보수법에서 모두 5
(1011은 십진수에서는 11, 0101의 보수이므로 2의 보수법에서는 -5)
* MSB (MostSignificantBit)
어떠한 데이터형의 최상위 비트
LSB (ListSignificantBit)
어떠한 데이터형의 최하위 비트

2의 보수 구하는 방법
- 1의 보수 : 대상 2진수의 0을 1로, 1을 0으로 치환
- 2의 보수 = 1의 보수 + 1
- ex. 0101의 2에 대한 보수는?
- 1. 0->1, 1->0으로 반전 => 0101 -> 1010
- 2. 결괏값에 +1 => 1010+ 1 -> 1011
위를 반대로 진행하면 2의 보수로 표현된 이진법의 음수의 절댓값을 알 수 있다.
(1011 (2진수 -5)를 통해 0101(2진수 5)를 확인)
4. 기본형(primitive type)
4.1 논리형 - boolean
- boolean의 값은 true / false 2가지만 존재
- 기본값(default) : false
- 논리 구현에 주로 사용
- 1bit로도 표현이 가능하지만, Java의 데이터 최소 단위는 byte이기 때문에 1byte 할당
4.2 문자형 - char
- 단 하나의 문자 저장
- 문자는 유니코드 형식의 정수가 저장됨
- 음수를 나타낼 필요가 없으므로 수의 표현 범위는 0~216-1
- ex.
char chr = 'A';
int num = 65;
'A'의 유니코드 번호는 65이므로 'A'는 65로 변환되어 chr에 저장
출력 시에는 변수 타입을 통해 원래의 리터럴형으로 반환하기 때문에
chr과 num의 출력 값은 각각 'A', 65로 다르다.
인코딩과 디코딩(encoding & decoding)
- 인코딩
- 문자를 숫자(유니코드)로 변환
- 디코딩
- 숫자(유니코드)를 문자로 변환
- 인코딩 방식(유니코드)과 디코딩 방식이 동일해야 원하는 결과를 얻을 수 있음
- (인코딩에 사용된 표와 디코딩에 사용된 표가 다를 경우 원하는 결과를 얻을 수 없음)
- 인터넷을 하다가 글자가 깨지는 이유의 대부분은
- 웹브라우저의 인코딩 설정과 웹페이지(html)의 인코딩 설정이 다르기 때문에 발생
아스키(ASCII)
- American Standard Code for Information Interchange - 정보 교환을 위한 미국의 표준 코드
- 128개의 문자를 제공하는 7bit 부호
- 처음 32개는 제어문자(control character) - 출력 불가능
- 마지막 문자(DEL)를 제외한 나머지 문자는 출력 가능 - 0~9, A~Z, a~z가 연속적으로 배치
확장 아스키 (Extended ASCII)와 한글
- 데이터의 단위는 byte이므로 7bit인 ASCII에 1byte를 확장한 2byte 부호
- 여러 국가와 기업에서 서로의 필요에 따라 다르게 정의해서 사용 가능
- CP949
- 완성형 한글이 모두 저장되어있는 문자 인코딩
- 윈도우에서 사용하는 기본 인코딩
- (자세히 알고 싶으면 직접 검색)
코드 페이지(code page, cp)
- 여러 버전의 확장 아스키에 대한 numbering을 위한 방식
- CP xxx와 같은 식으로 명명
- 한글 윈도우 : CP949, 영문 윈도우 CP437 사용
유니코드(Unicode)
- 인터넷의 발명에 따라 전 세계의 모든 문자를 하나의 통일된 문자 집합으로 표현한 방식
- 21bit (200만 개의 문자)
- 보충 문자 (참고)
- 새로 추가된 문자들을 통칭
- 보충 문자는 char형이 아닌 int형으로 출력해야 함
- 유니코드 인코딩의 종류 : UTF-8, UTF-16, UTF-32
- UTF-8
- 하나의 문자를 1~4byte의 가변크기로 표현
- 영어와 숫자 : 1byte
- 한글 : 3byte
- 문자의 크기가 가변적이라 다루기 어렵다는 단점이 존재
- UTF-16
- 문자를 최소 2byte로 표현
- 영어와 숫자 : 2byte
- 한글: 3byte
- 인터넷에서는 전송속도가 중요하므로 문서의 크기가 작을수록 유리 => UTF-8이 대중적
4.3 정수형 - byte, short, int, long
- byte = 1byte, short = 2byte, int = 4byte, long = 8byte
- 기본자료형(default data type) = int
정수형의 표현 형식과 범위
- 모든 리터럴은 변수에 2진수로 바뀌어 저장
- 이 방식은 크게 정수형과 실수형
- nbit로 표현할 수 있는 정수의 개수 = 2n
- nbit로 표현할 수 있는 정수의 범위 : -2n-1 ~ 2n-1 - 1 (4bit 2진수 1000 ~ 0111 즉, -8 ~ 7)
정수형의 선택 기준
- JVM의 피연산자 스택(operand stack)이 피연산자를 4byte단위로 저장 -> int사용이 효율적
- 따라서 int보다 작은 byte, short는 사용 자제 (성능보다 저장공간 절약이 중요할 때 사용)
- long 타입의 범위를 벗어나는 값 => BingInteger 클래스 사용
정수형의 오버플로우
- 4bit 2진수 1111에 4bit 2진수 0001을 더하면 10000이 되고
메모리 공간이 4bit 이므로 1을 제외한 0000이 저장 - 2진수의 overflow
- 2의 보수법 미적용 (4bit 이진수의 범위 : 0 ~ 15)
0000에서 0001을 뺄 경우 1111이 됨 - 2의 보수법 적용 (4bit 이진수의 범위 : -8 ~ 7)
-8에서 1을 뺄 경우
즉 1000에 1111을 더할 경우 0111 즉 7이 됨
(반대방향으로 overflow가 정상적으로 발생)
- 2의 보수법 미적용 (4bit 이진수의 범위 : 0 ~ 15)
- 이처럼 타입이 표현할 수 있는 값의 범위를 넘어서는 것 = 오버플로우(overflow)
- 2진수의 overflow 참고
https://actually94.tistory.com/220
다시 정리하면,
최댓값 + 1 은 최솟값,
최솟값 - 1 은 최댓값 이 된다.
부호 있는 정수의 오버플로우
- 2진수 기준, 부호 없는 정수는 0000이 될 때, 오버플로우가 발생
- 2진수 기준, 부호 있는 정수는 MSB(부호비트)가 1이 될 때 오버플로우가 발생
* println() 은 인자들을 기본형 리터럴로 변환하여 출력한다.
따라서 기본형이 아닌 변수에 대해서는 다음과 같이 형변환이 필요

4.4 실수형 - float, double
실수형의 범위와 정밀도

- 위는 양의 범위만 나타낸 것으로 부호비트(MSB)를 통해 음수 표현 시 양의 범위만큼 반대로 표현 가능
double을 예로 -4.9x10-324 ~ -1.8x10308까지 표현 가능 - 양의 범위와 음의 범위에 해당되지 않아 표현할 수 없는 수의 범위가 존재
double 기준 -4.9x10-324 ~ 4.9x10-324, float 기준 -1.4x10-45 ~ 1.4x10-45
실수형은 소수점도 표현하므로, 얼마나 큰 값을 표현하는지도 중요하지만, 얼마나 0에 가깝게 표현하는지도 중요

float : S(1bit) + E(8bit) + M(23bit) = 32bit
double : S(1bit) + E(11bit) + M(52bit) = 64bit
* 정밀도(precision)는 데이터의 손실 없음이 보장되는 정수의 자리 수와 소수 자리 수의 합이며
자료형에 대한 정밀도는 고정된 것이 아니라, 저장되는 리터럴 값에 따라 다르다.
(변수마다 가변 하는 값이기 때문에 숫자에 집착하지 말자)

float f1 = 12.01234567890123456789f;
float f2 = 123.456789f;
double d1 = 12.01234567890123456789;
System.out.printf("f1=%25.20f%n", f1); //정밀도 : 8
System.out.printf("f2=%25.20f%n", f2); //정밀도 : 8
System.out.printf("d1=%25.20f%n", d1); //정밀도 : 15
/*
f1= 12.01234531402587900000
f2= 123.45678710937500000000
d1= 12.01234567890123900000
*/위의 결과를 통해 확인할 수 있듯이,
정밀도까지의 값까지는 원래의 값이 저장되지만 그 이후의 값은 오차가 발생하게 된다.
ex. f1의 경우 12.012345까지만 원래의 값과 일치
실수형의 overflow
- 최댓값보다 큰 값으로 overflow
=> 값이 무한대 - 최솟값보다 작은 값으로 underflow
- => 값이 0
실수형의 저장 방식
- 부동소수점(floating-point)의 형태로 저장 (±M x 2E)
- 부호 (Sign bit)
0 : 양수, 1 : 음수
2의 보수법을 사용하지 않기 때문에, 부호를 변환할 때 부호비트만 바꾸면 된다. - 지수 (Exponent)
지수는 부호 있는 정수이므로 float 기준 -127~128의 범위를 표현 가능
-127과 128은 NaN(Not a Number), POSITIVE_INFINITY, NEGATIVE_INFINITY가 예약
따라서 실질적으로 사용 가능한 지수의 범위 : -126 ~ 127
최댓값 : 2127 * 2(1 <= 가수의 범위 <2) ≒ 1.7x1038 * 2
최솟값 : 2-126 * 1 ≒ 1.17x10-38
* 지수부의 -127을 사용하면 이 책에서 언급한 1.4 x 10-45까지 표현 가능
이는 아래 URL의 댓글에 책 스크린샷을 통해 확인
https://cafe.naver.com/javachobostudy - 가수 (Mantissa)
실제 값을 저장하는 부분, 2의 23승은 대략 7자리의 10진수로 변환 가능 => float의 정밀도
부동소수점의 오차
오차가 발생하는 경우 :
- 실수가 무한소수인 경우
- 유한 소수를 2진수로 변환했을 때 무한소수가 되는 경우
- 유한소수이더라도 소수점 아래의 개수가 가수보다 많을 경우 (버려짐으로 오차 발생)
실수를 부동소수점으로 변환 과정
- 9.1234567 => 1001.0001111....
- 정규화 (1.xxx X 2n 형태로 변환)
1.0010001111 x 23
정규화된 2진수의 정수부는 항상 1이므로 이를 제외한 소수부의 23자리를 가수로 저장
지수는 기저법 (n에 127을 더하여 저장)으로 저장.
즉 3 + 127 = 130이 2진수로 변환되어 저장 - 결과
| 0 | 100 0001 0 | 001 0001 1111 1001 1010 1101 |
S E M
이때 발생할 수 있는 최대 오차는 2-23 = 0.0000001192(약 10-7)이므로 float의 정밀도는 7자리
5. 형변환
5.1 형변환(캐스팅, casting)이란?
변수나 리터럴의 타입을 다른 타입으로 변환하는 것
5.2 형변환 방법
형변환하고자 하는 피연산자(변수, 리터럴)앞에 원하는 데이터 타입을 괄호와 함께 삽입
(이때의 괄호를 형변환 연산자 또는 캐스팅 연산자라고 함)
(type)피연산자
double d = 123.456;
int i = (int)d; //123 형변환시 소수점 이하값 버림- 기본형(primitive type)간에는 boolean을 제외하고 모두 형변환이 가능
- 기본형(primitive type)과 참조형(reference type)간의 형변환은 불가능
5.3 정수형간의 형변환
큰 타입에서 작은 타입
- 예를 들어 short에서 byte로의 형변환의 경우,
작은 타입의 bit수를 초과하는 큰 타입의 bit값들은 버려진다.

작은 타입에서 큰 타입
- 값의 손실이 없다. (형변환 연산자 불필요)
- 또한 작은 타입의 값이 음수일 경우, 변환 시 부호를 유지할 수 있도록 빈 공간을 1로 채움

short s;
byte b = -1;
s = b;
System.out.printf("byte 변수 b의 값 -1이 short로 형변환됐을 때를 2진수로 확인\n");
System.out.println(Integer.toBinaryString((short)s));
//11111111111111111111111111111111
5.4 실수형 간의 형변환
- 부호부(S)
그대로 저장 - 지수부(E)
기저법이 적용되어 있으므로 (float의 기저 = 127, double의 기저 = 1023)
float to double 시 지수부 - 127 + 1023으로 변환 후 저장
double to float 시 지수부 - 1023 + 127으로 변환 후 저장 - 가수부(M)
float to double 시 가수 23자리를 채우고 나머지는 0으로 채움
double to float 시 가수의 24번째 자리에서 반올림이 발생
float타입을 넘는 double 값을 float으로 형변환 시 결과는 ±무한대 or ±0
추측인데 변환된 지수부의 값이 float의 범위를 양의 범위로 넘으면 Infinity,
음의 범위로 넘으면 0이 나오도록 설계돼있지 않을까...
double d1 = 1.0e100;
float f1 = (float)d1;
System.out.printf("f1=%25.20f\n", f1);
double d2 = 1.0e-50;
float f2 = (float)d2;
System.out.printf("f1=%25.20f\n", f2);
5.5 정수형과 실수형 간의 형변환
정수형을 실수형으로 변환
- 정수를 정규화한 후 실수의 저장 형식으로 저장
- 실수형의 범위가 정수형보다 넓기 때문에 변환 과정에서 큰 문제는 없다.
다만, 실수형의 정밀도 제한으로 인한 오차는 발생할 수 있다.
ex. int형의 최댓값은 약 20억으로 최대 10자리의 정밀도를 요구,
but float형은 약 7자리의 정밀도 이므로 오차가 발생 (double 사용 권장)

실수형을 정수형으로 변환
- 간단하게 소수점이 버려진다.
정규화 이전의 형태로 변환하고 정수 부분만 정수형에 저장
ex. 9.1234567의 경우 | 0 | 100 0001 0 | 001 0001 1111 1001 1010 1101 | 과 같이 실수형에 저장되어 있는데
정규화 이전의 형태인 1001.0001111.... 로 변환 후
1001만 정수형에 저장 (9만 저장, 즉 10진수 기준으로 소수점 값이 버려짐)
5.6 자동 형변환
- 변수가 저장할 수 있는 값의 범위보다 더 큰 값을 저장하려고 할 경우가 아니면 자동 형변환이 발생
(컴파일러가 생략된 형변환을 자동적으로 추가)
ex. float f = 100은 컴파일 시
float f = (float)100과 같이 형변환이 자동 추가 - 변수가 저장할 수 있는 값의 범위보다 더 큰 값을 저장하려고 할 경우
값의 손실이 발생하므로 에러가 발생하고 따라서 명시적 형변환이 필요

- 서로 다른 두 타입 간의 연산의 경우
두 타입을 표현 범위가 더 넓은 타입으로 변환 후 연산 (산술 변환)
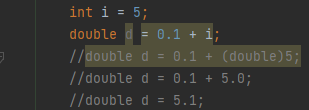
자동 형변환 규칙
컴파일러가 기존의 값을 최대한 보존할 수 있는 타입으로 자동 형변환
즉, 표현 범위가 작은 타입에서 넓은 타입으로 형 변환 시에는 값의 손실이 없으므로 자동 형변환이 발생

- short와 char은 크기는 같으나 표현 범위가 다르기 때문에 자동 형변환이 불가능
(short는 양수와 음수 모두 표현, char은 양수만 표현) - long이 float보다 자료형의 크기는 크지만, 실수형인 float이 정수형인 long보다 표현 범위가 넓기 때문에
long to float은 자동 형변환이 가능 (당연한 얘기지만, float to long은 자동 형변환 불가)
연습문제
'Java > Java의 정석' 카테고리의 다른 글
| [Java의 정석]Chapter 01. 자바를 시작하기 전에 (0) | 2022.10.26 |
|---|---|
| Chapter 04. 조건문과 반복문 (0) | 2022.04.10 |
| Chapter 03. 연산자(Operator) (0) | 2022.04.10 |
| Chapter 02. 변수(Variable) (0) | 2022.04.10 |

댓글